
LangChain文档OA系统与提示工程

LangChain文档OA系统与提示工程
Beaten知识梳理
首先梳理下用LangChain快速构建基于“易速鲜花”本地知识库的智能问答系统
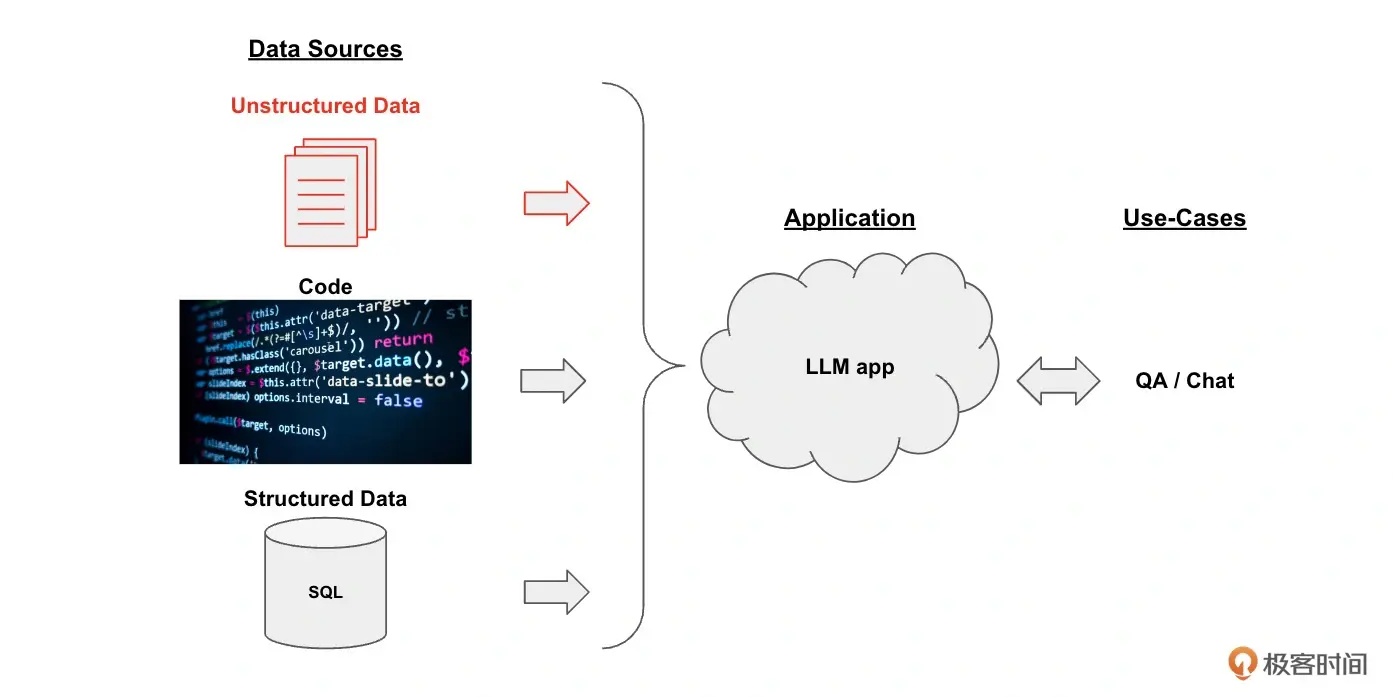
整个框架分为三部分:
数据源、大模型、用例
核心实现机制: 数据处理管道(Pipeline)
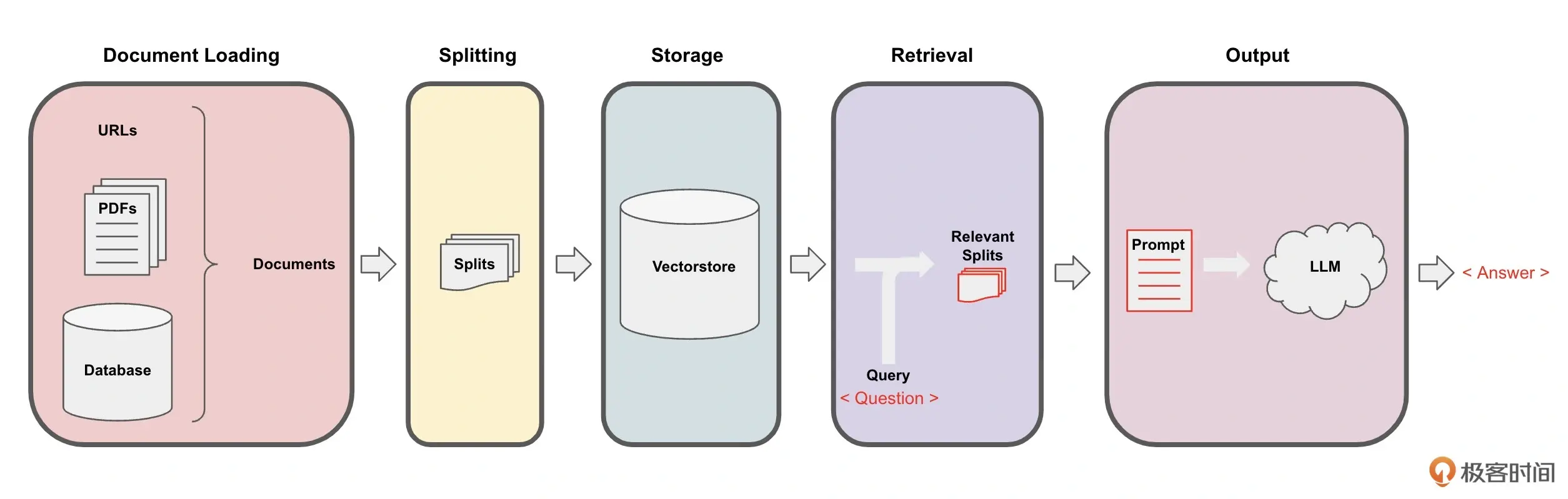
每一步的具体流程:
1.loading documents
2.splitting documents -> “文档块””文档片”
RecursiveCharacterTextSplitter
3.以嵌入的形式(embedding)storage -> Vector DB
涉及大量非结构化数据,如图
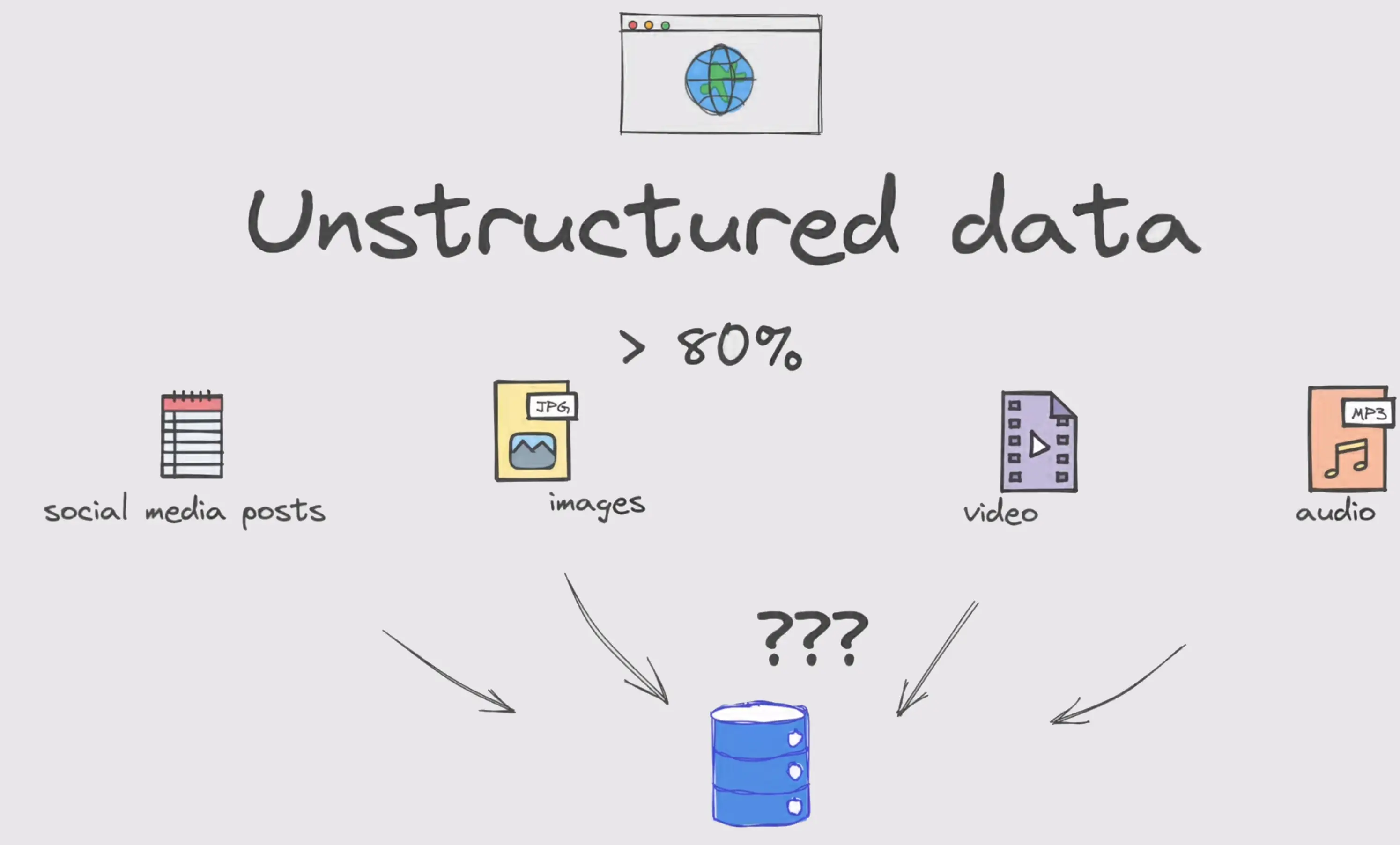
向量数据库存储。什么是词嵌入?
将文本或词语转换成向量,其优点是提供了一种将文本数据转化为计算机可以理解和处理的形式,并且保留词语之间的语义关系。提及到:自然语言处理->文本分类、机器翻译、情感分析
4.retrieval
检索,相关信息的获取。把问题也转换为向量,去和数据库里的向量作比较。
欧式距离、余弦相似度:方向反映语义,越接近1,向量方向越接近。
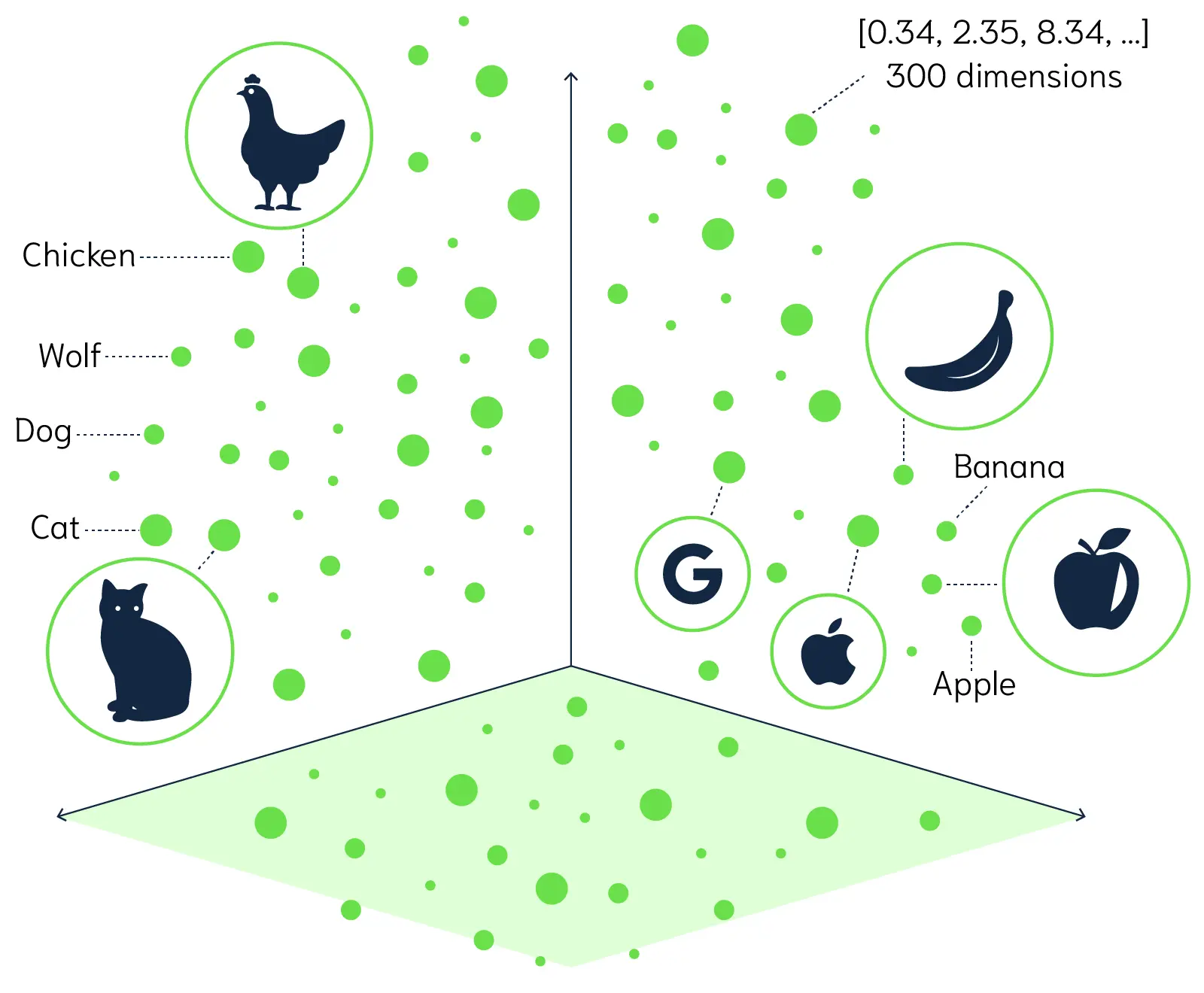
数量大小差异用欧式距离,文本语义差异用余弦相似度
创建一个检索式问答模型,这里需要创建RetrievalQA链。
5.output
Few-Shot(少样本)- One-Shot(单样本)-Zero-Shot(零样本)
大家或许可能会联想到Machine learning/Deep learning 中的小样本学习,是的没错!这个概念的产生基可以顾名思义,我们往往无法获取到大量的标签化数据。
在LangChain的提示工程(Prompt Engineering)中,小样本学习的思想也被广泛应用,即Few-Show和Zero-Shot。
- 在Few-Shot学习设置中,模型会被给予几个示例,以帮助模型理解任务,并生成正确的响应。
- 在Zero-Shot学习设置中,模型只根据任务的描述生成响应,不需要任何示例。
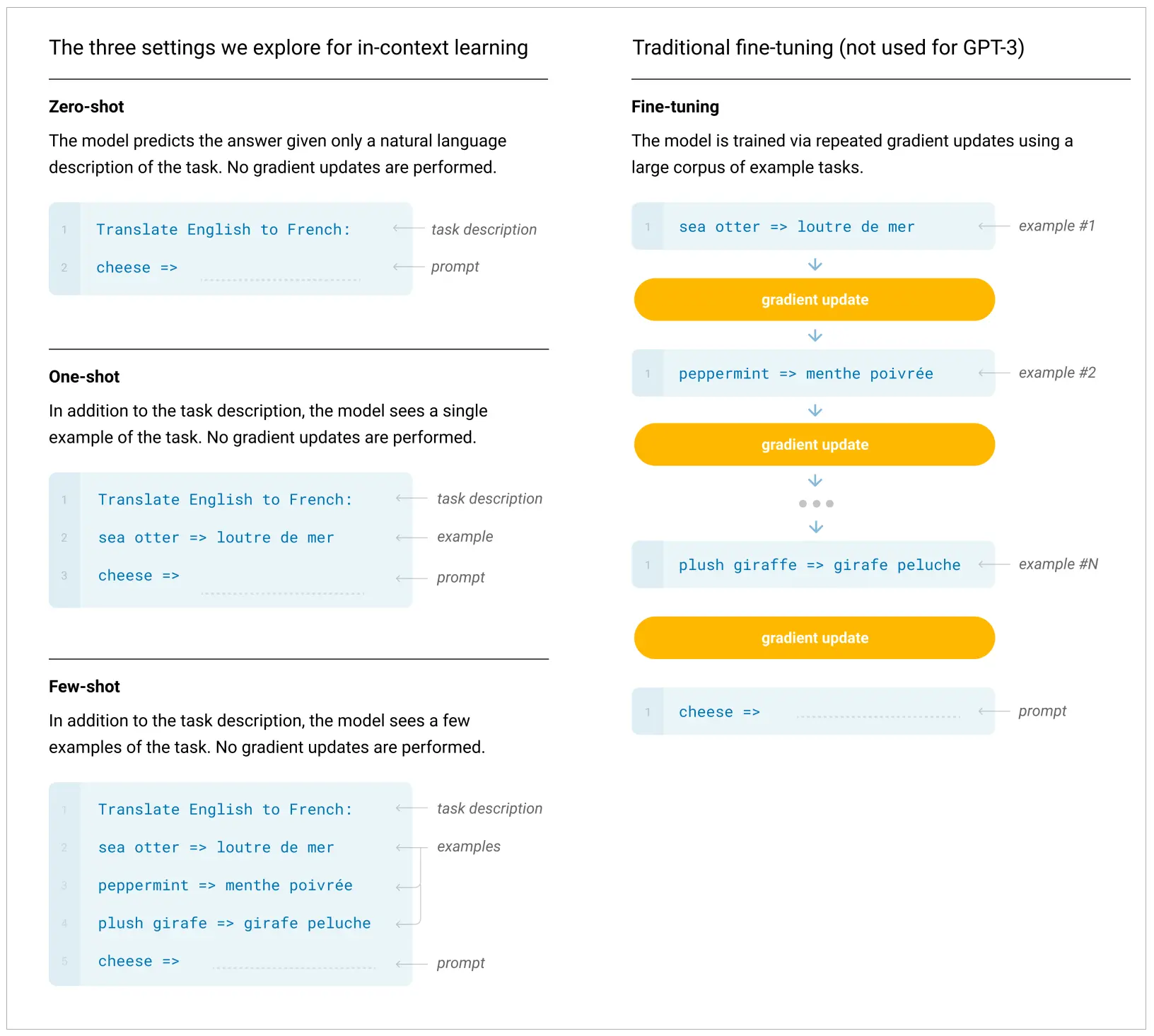
上图是OpenAI的GPT-3论文给出的GPT-3在翻译任务中,通过FewShot提示完成翻译的例子。
当然如果少样本提示的效果不佳时,可能会导致模型在任务的学习上不充分,从而无法得到想要的结果。
这个可以当成算法题中给的样例,仅仅通过题面或许不能够完全理解题意或者给出解决方案,当拿到几个样例后就不一样了。
CoT思维链
顾名思义我们又可以得知,相较于上面加入了推理过程。
思维树(Tree of Thoughts,ToT)框架
Model I/O中的第二个子模块,LLM
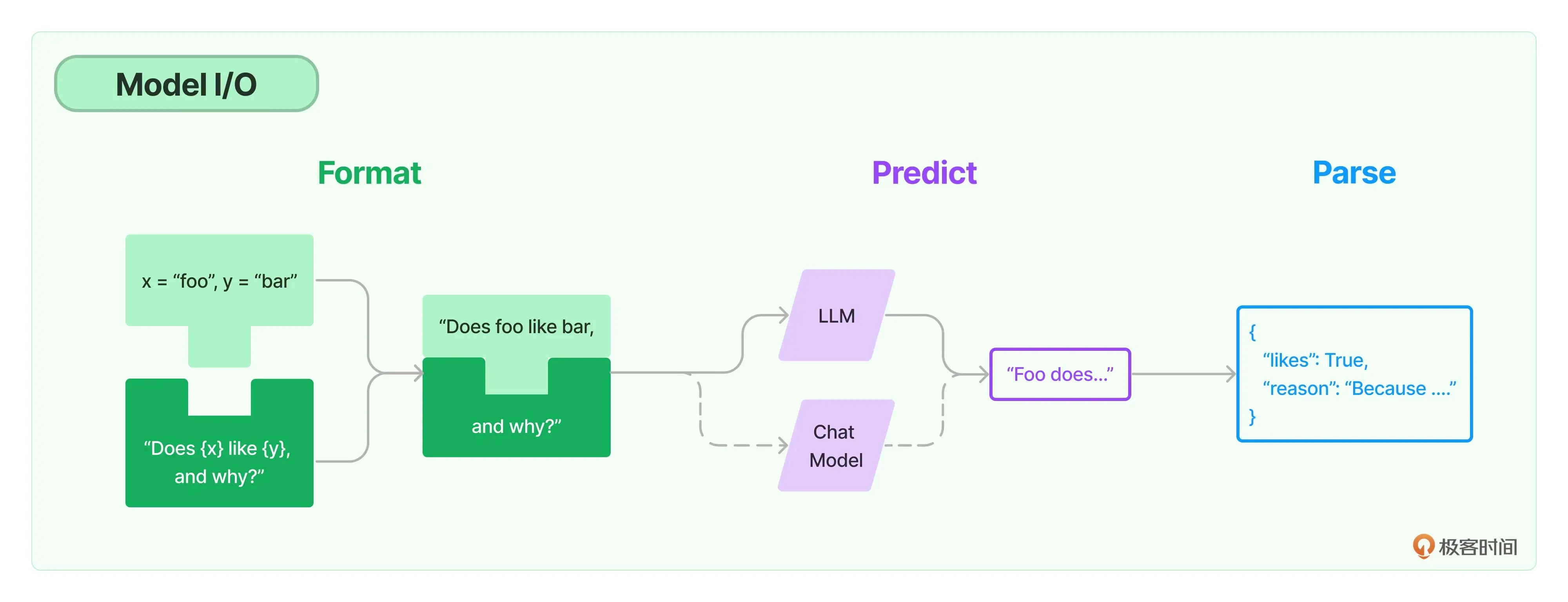
对于大模型的微调远远比从头训练一个模型更加省时高效!
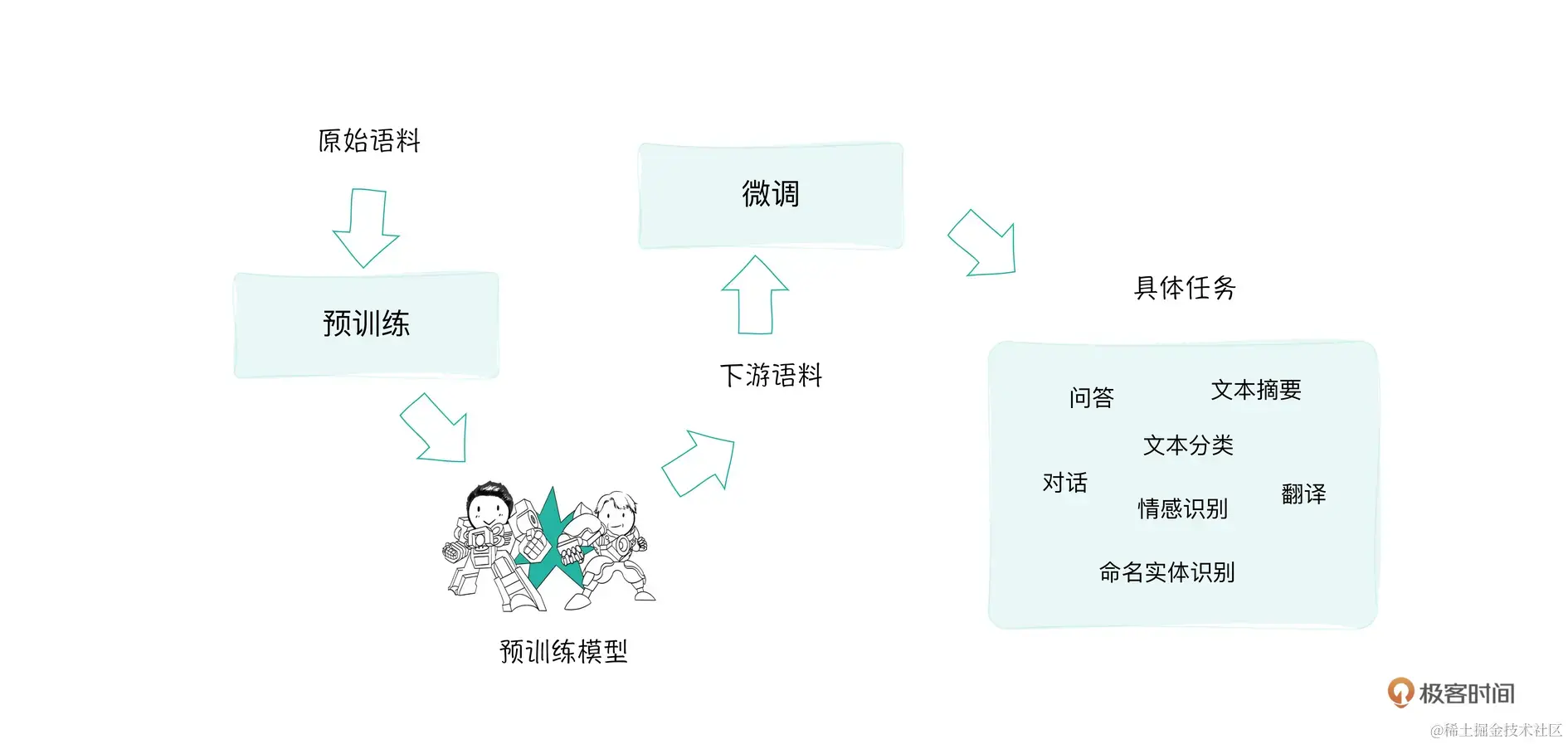
图中的具体任务总结来说就是预训练与微调。
关于微调,为什么要微调呢?因为面对不同的下游任务所涉及的领域不同,为了使得模型有所针对性,进行模型微调变成垂类模型,即微调模型做垂直领域,就是这么简单!





